YouTube Live 2008/11/22
It’s fun - not sure what I think - will there be a service?
But, for now it’s fun.
It’s fun - not sure what I think - will there be a service?
But, for now it’s fun.
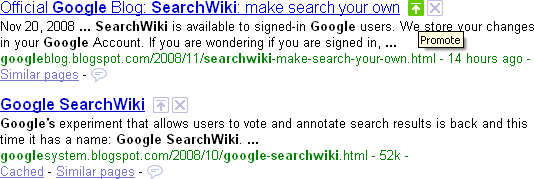
This has been a long time coming, but I login today, and low and behold, SearchWiki.
I was following some testing they were doing on this years ago, but honestly this came as a total suprise to me today - and woke up my urge to blog.
More when I read up.

Just catching up - with even the Boston Globe taking a retrospective shot at the Cuil launch today, I thought I’d get in mine. If you remember much of the positive press on Cuil focused on their boasts that their new index is far larger than any of the competition:
Cuil is claiming to have the largest index of the web, 120 billion pages indexed (with a total of 186 billion seen by its crawler; spam and duplicate content are among things excluded from what gets indexed). In talking with them, Cuil estimated they were three times the size of Google.
Sounds pretty awesome, right?
Well, I missed this too, but apparently these bold claims were enough to rattle an indirect response out of the Googleplex later in the week, releasing the size of their index for a first time in a long time:
Recently, even our search engineers stopped in awe about just how big the web is these days – when our systems that process links on the web to find new content hit a milestone: 1 trillion (as in 1,000,000,000,000) unique URLs on the web at once!
No disrespect to Cuil, they could still give Google a run for it’s money - they’ve definitely got the arrogance part down, apparently just not so well-endowed in the index department as they thought they were.
Thanks for the server, Randy - this is lighttpd running wordpress, drupal, and mediawiki.
